Azure Site Recovery – VMWARE (3)
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou.
V této části článku se budeme zabývat přidáním VMWARE vCentra, vytvořením PROTECTION GROUP a přidáním virtuálních strojů do vytvořené PROTECTION GROUP.
1.**Přidání vCenter serveru
Ve chvíli kdy máme pověřovací údaje (jen friendly name) úspěšně synchronizovány do Azure, můžeme přistoupit k dalšímu nezbytnému kroku a to přidání VMWARE vCenter do Azure. Tento krok nám umožní načítat seznam virtuálních strojů, které spadají pod konkrétní vCenter. A dále je možná detekce stavu virtuálních strojů. Tedy v sekci „SERVERS“ – „CONFIGURATION SERVERS“ vyberte konkrétní management server, v ném případě „ONPREMISEPS“ a v dolní části okna klikněte na tlačítko „ADD VCENTER SERVER“.

**
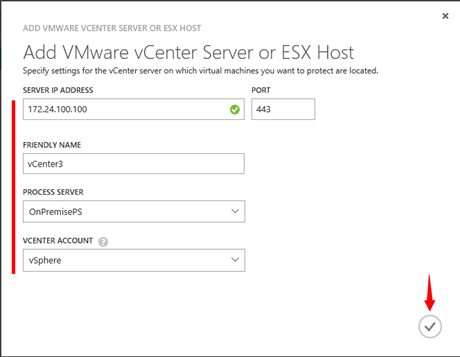
V okně pro přidání vCenter serveru doplňte údaje vašeho On-Premise vCenter serveru. Jako Process server jsem vybral On-Premise server „ONPREMISEPS“ a v rámci položky „VCENTER ACCOUNT“ jsem vybral v předchozím kroku vytvořené/definované pověření.
**
Pravděpodobně i v případě této akce, tedy přidání vCenter serveru, nepotřebujete mít navázánu/funkční Site-to-Site VPN (případně ExpressRoute). Pokud se spletete a zadáte např. špatnou IP adresu vCenter serveru, dojde v rámci spuštěné úlohy v sekci “JOBS” k vygenerování chyby. A ta říká, že vCenter, který chcete přidat, musí být dostupný přes výchozí port TCP 443 z Process/management serveru v On-Premise prostředí.
**
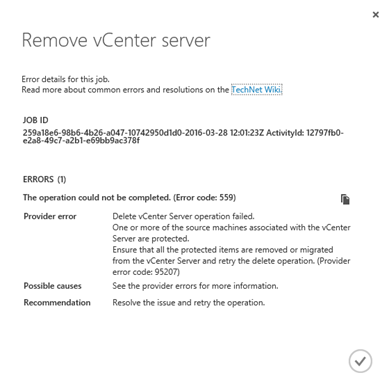
Pokud se rozhodnete odebrat stávající vCenter server, musíte nejprve zrušit replikaci všech virtuálních strojů, které jste přidaly „skrze“ toho vCenter, viz chyba níže.
**
Po rozkliknuti management serveru, lze vidět seznam vCenter serverů navázaných na tento konkrétní management server.
**
Pokud vyberete konkrétní přidaný vCenter, máte možnost jej odstranit, nebo upravit jeho parametry, pokud došlo k jejich změně.
**
2.**Vytvoření Protection Group
Dalším krokem je vytvoření Protection Group. Je velmi důležité si zde uvědomit co je Protection Group. Je to skupina virtuálních strojů, které budeme v rámci jedné skupiny replikovat do Azure. Přičemž každá skupina sdílí určité kritické parametry týkající se možnosti obnovení. Je vhodné umístit do jedné skupiny virtuální servery s podobnými požadavky na možnosti obnovení, jako jsou například RPO, Retention, Application Snaphot frequency apod.
Poznámka: Vše bude vysvětleno dále.
V sekci „PROTECTION ITEMS“ vyberte položku „PROTECTION GROUPS**“.

V dolní části okna pak klikněte na tlačítko „+ PROTECTION GROUP“

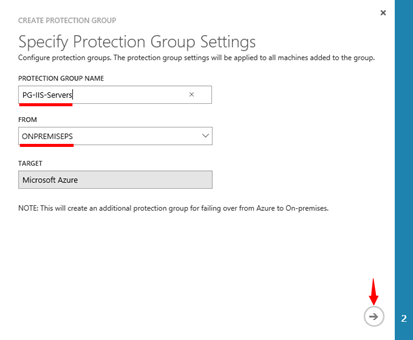
V průvodci přidáním „PROTECTION GROUP“ zadejte nejprve název nové skupiny do pole „PROTECTION GROUP NAME“. Dále v poli „FROM“ vyberte odkud se budou virtuální stroje replikovat. V mém případě jsem vybral management server „ONPREMISEPS“. Přičemž cíl je v tomto případě Azure a nelze jej změnit.
**
Na další kartě průvodce definujeme kritické parametry skupiny.
Položka „MULTI VM CONSISTENCY“ – pokud je nastaveno na „ON“, bude docházet k vytváření sdílených aplikačně-konzistentních bodů obnovení skrze všechny virtuální stoje v dané skupině. Tuto volbu je vhodné zapnout v případě, že na virtuálních strojích v dané skupině jsou servery, kde běží stejné, nebo podobné aplikace či služby. Tedy například Webové servery. Výhodou je pak, že všechny virtuální stroje v rámci skupiny budou obnoveny současně do stejného bodu obnovení, tak aby bylo docíleno datové/aplikační konzistence.
RPO threshold – RPO v podstatě zjednodušeně řečeno uvádí časovou periodu, ve které mohou být data ztracena, aniž by to znamenalo pro nás kritický problém/incident. Ve výchozím stavu je RPO treshold nastaven na 30 minut. To znamená, že pokud se replikace opožďují, nebo neprobíhají správně a není možné zajistit, že v Azure existují replikovaná data ne starší než 30 minut, dojde k vygenerování upozornění. Pak tedy hrozí, že v případě neplánovaného Failoveru/výpadku On-Premise prostředí, budeme mít k dispozici data starší než 30 minut, nebo než námi požadované RPO. Minimum, které lze nastavit je 1 minuta. Maximum pak 240 minut.
Recovery point retention – jedná se časový interval/okno ve kterém dochází k uchovávání jednotlivých bodu obnovení. A znamená to, že se lze vrátit k jakémukoli bodu obnovení v tomto časovém okně. Výchozí hodnota je 24 hodin. Pokud tedy zjistíme, že například před méně než 24 hodinami došlo v důsledku lidské chyby k nenávratnému poškození aplikačního serveru, který je replikován do Azure, lze spustit pro tento server FAILOVER proceduru „a vrátit se v čase“ do bodu, kdy byl aplikační server funkční. Minimum je jedna hodina, maximum pak 72 hodin.
Ukázka Failover procedury, kdy si vybereme „Custom recovery point“.
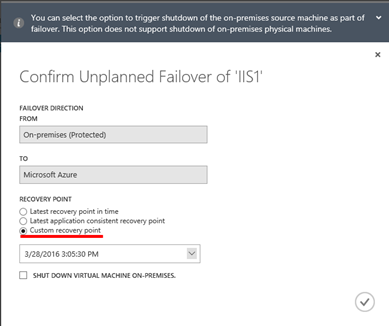
Na výběr pak máme jak z klasických bodu obnovení, tak z Aplikačně konzistentních bodu obnovení, viz také další volba.
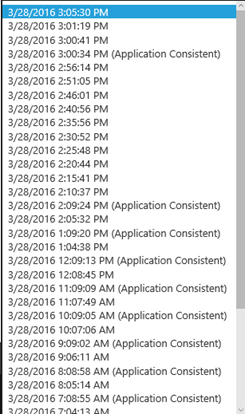
Application-consistent snapshot frequency – udává, jak často se má vytvářet aplikačně konzistentní bod obnovení. Předpokládám, že v případě Windows operačních systému, je díky Mobility service zavolán nějaký konkrétní VSS provider a dojde k dočasnému zmražení všech transakcí a aplikace jsou donuceny se uvést do konzistentního stavu, což by mělo umožnit zálohu konzistentních dat. Přiznám se, že nemám zjištěno, zda jsou možné aplikačně konzistentní body obnovení i v případě Linux operačního systému, ale domnívám se, že ne. Výchozí hodnota je 60 minut. Tedy s pomocí Mobility service, bežící na replikovaném virtuálním stroji se pokusí každou hodinu vytvořit aplikačně konzistentní bod obnovení. Minimální hodnota je „NEVER“, tedy to znamená, že se nebudou vytvářet aplikačně konzistentní body obnovení. Druhá nejnižší možná hodnota je pak 20 minut, a nejvyšší hodnota pak 1440 minut (24 hodin).
**
Pokud odsouhlasíme vytvoření „PROTECTION GROUP“, automaticky pak dojde vytvoření i druhé skupiny s „označením“ „Failback“ na konci. Failback bude popsán později v článku.
**
3.**Přidání virtuálních strojů do Protection Groups
Dalším krokem je pak přidání konkrétních virtuálních strojů do Protection Group.
POZOR!!! Jakmile přidáte virtuální stroj do protection group, dojde okamžitě k jeho replikaci do Azure. Tedy pro tento úkol je vhodné zvolit dobu, kdy je nejmenší zatížení vašeho On-Premise prostředí. Obvykle to jsou noční, nebo večerní hodiny.
Vybereme konkrétní PROTECTION GROUP, a „vstoupíme do ní“. Zde pak klikneme na položku „ADD VIRTUAL MACHINES“,

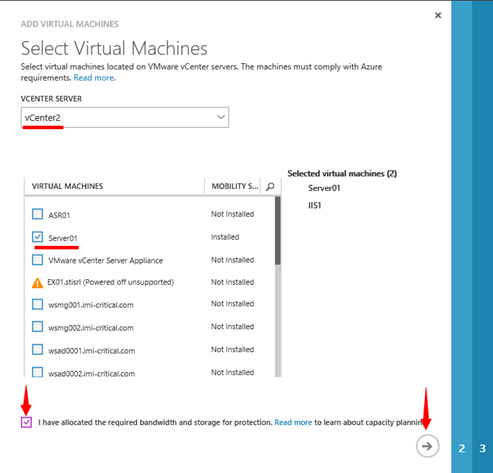
V průvodci přidáním virtuálních strojů nejprve vybereme správný vCenter server. Na základě výběru vCenter serveru, se nám načte seznam virtuálních strojů. Upozornění: Seznam virtuálních strojů je ovlivněn standardním 15 minutovým oknem, v rámci kterého dochází k načítání dat z management serveru. Tedy pokud vytvoříte virtuální stroj a vzápětí jej budete chtít přidat, v seznamu virtuálních strojů jej neuvidíte. To lze řešit pomocí tlačítka „REFRESH“, viz také postup popsaný výše v článku. Zde je vidět, že je možnost vybrat pouze ty virtuální stroje, které jsou podporovány. Standardně to nejsou všechny virtuální stroje, které jsou vypnuté. Což je logické, protože PROCESS SERVER, potřebuje vzdáleně na tyto virtuální servery instalovat Mobility service. Vybereme konkrétní podporované virtuální stroje a dále musíme souhlasit s tím, že jsme si vědomi náročnosti replikace a jejího dopadu na naši infrastrukturu.
**
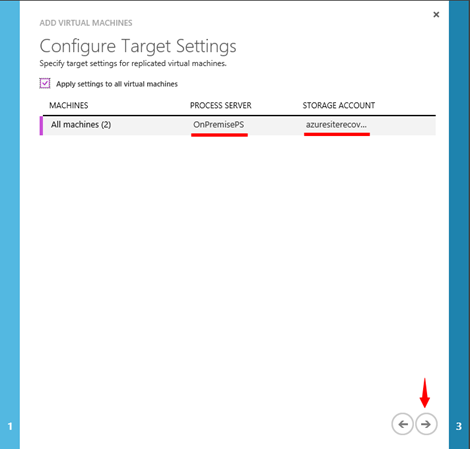
Na další kartě pak vybereme PROCESS SERVER, který bude replikaci řídit a dále vybereme Storage Account v Azure, kam budou nově vzniklé .vhd soubory ukládány.
**
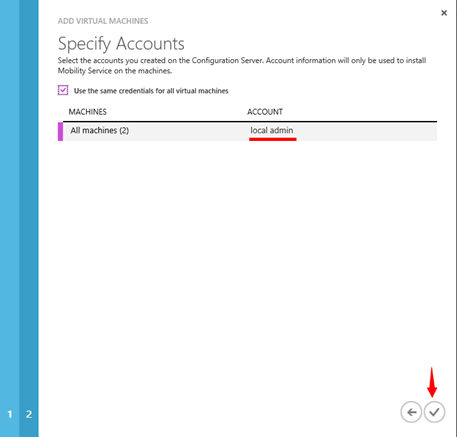
Na další kartě průvodce pak vybereme pověření pro námi vybrané virtuální stroje, které nám umožní instalaci Mobility service.
**
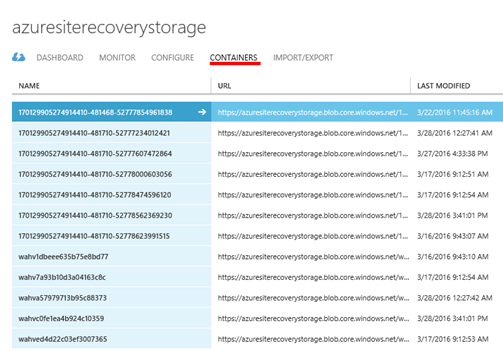
Zde pak ukázka obsahu storage account, kam jsou replikovány virtuální stroje.
**
Vidíme, že na storage accountu je uložen vhd disk virtuálního stroje replikovaného z On-premise prostředí. Tento soubor se pak použije v případě Test Failover, nebo Failover operace.
Níže pak vidíte VHD location string disku virtuálního stroje Server1, který je ve stavu Unplaned Failover.
https://azuresiterecoverystorage.blob.core.windows.net/wahva57979713b95c88373/copied-%7B2057439281%7D.vhd
**
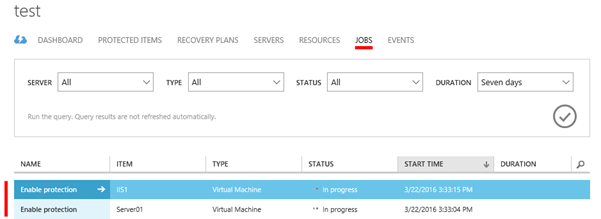
Jakmile je virtuální stroj přidán do PROTECTION GROUP, dojde k sekci „JOBS“ ke spuštění úlohy, která se pokusí s nastavenými pověřeními o instalaci Mobility service na vybrané virtuální stroje.
**
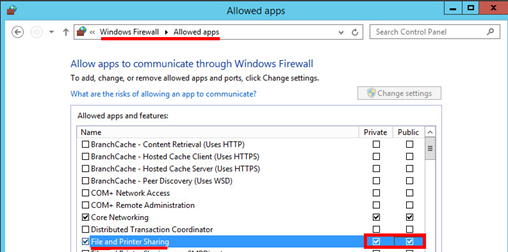
Pokud se má instalace Mobility service povést, musí být v případě podporovaného Windows operačního systému správně nastaven Firewall. Tedy musí být pro aktivní Firewall profil povoleno „File and Printer Sharing“ a dále povoleno pravidlo pro „Windows Management Instrumentation (WMI)“. Následně pak musí být povolen port TCP 9443, pro komunikaci a přenos dat mezi Mobility service a PROCESS SERVEREM.
**
**
Zde je pak ukázka úspěšně dokončené úlohy
**
V sekci „PROTECTED ITEMS“, „PROTECTION GROUPS“, vstupte do konkrétní skupiny. A dále vstupte do vlastností konkrétního virtuálního serveru.
**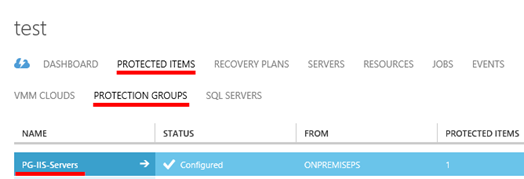
Jakmile je úspěšně dokončena instalace Mobility service, dochází k replikaci dat do Azure. Na obrázku je podrobně vidět jaké disky se replikují, kdo je zdroj dat a jaký proces server tyto data zpracovává.
**
Je samozřejmě možné do stávající skupiny přidat další virtuální stroje. Stačí, když vstoupíte do konkrétní skupiny a v dolní části okna vyberete tlačítko „ADD MACHINES“.
**
**
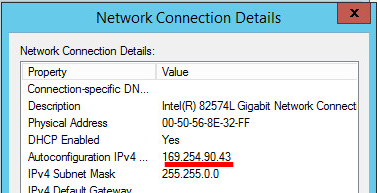
Na obrátku pak vidíte ukázku toho, že ASR si detekuje i různé stavy virtuálních strojů v On-premise prostředí. V tomto případě nemůžeme přidat do skupiny virtuální stroj, protože na neplatnou IP adresu.
**
Z výpisu IP konfigurace na tomto virtuálním stoji je patrné, že nebyl schopen získat IP adresu z DHCP serveru a proto si nastavil APIPA IP adresu. Která ovšem není routovatelná.
**
**