Azure Site Recovery – VMWARE(6)
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou. V této části článku se budeme zabývat procedurou FAILOVER, FAILBACK a přidáním dalšího PROCESS SERVERu do Azure.****
1.**Failover
V případě, že dojde k problémům v On-Premise prostředí, je možné inicializovat Failover proceduru. Resp. prostřednictvím RECOVERY PLAN spustit proceduru nastartování virtuálních strojů v Microsoft Azure. A tím zpřístupnit produkční servery a na nich běžící služby a aplikace interním klientům. A to buď prostřednictvím VIP IP adres a vytvořených Endpointů, nebo pak prostřednictvím Site-to-Site VPN. Samozřejmě s touto procedurou se váže spousta i jiných úskalí. Například změny DNS záznamů, přesměrování komunikace apod. Je třeba si uvědomit, že dojde k obnovení produkčních virtuálních strojů do virtuální sítě v Microsoft Azure. A tudíž je třeba pro On-Premise klienty zajistit za těchto nových podmínek kontinuitu ve využívání aplikací a služeb.
Nejprve je ale třeba nastavit replikované virtuální stroje. V sekci „PROTECTED ITEMS“ – „PROTECTED GROUPS**“ vyberte konkrétní skupinu a vstupte do ní.
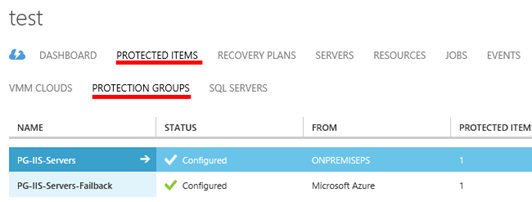
Pak v rámci skupiny vyberte jednotlivé virtuální stroje replikované do Azure. Vstupte do konkrétního virtuálního stroje.
**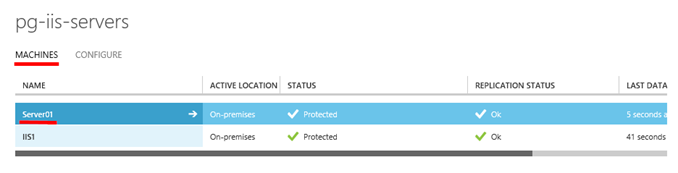
Zde pak přejděte do sekce „CONFIGURE“
**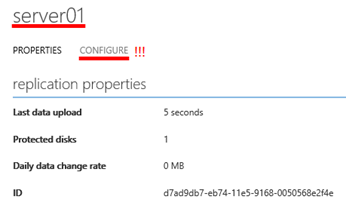
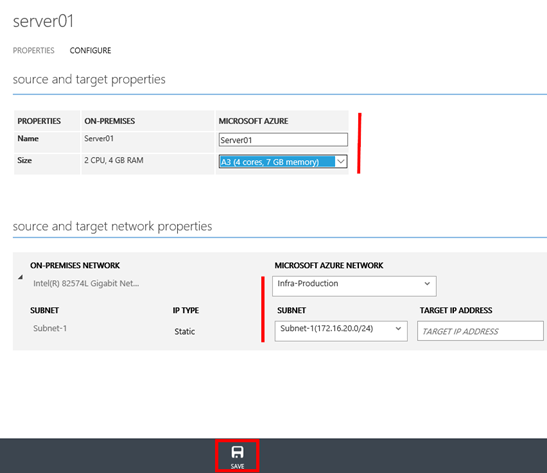
Zde je pak nutné nastavit parametry virtuálního stoje. Jednak zde v první části, změnou parametru „Size“ můžete ovlivnit velikost budoucího virtuálního stroje, který bude nastartován v Azure v rámci procedur „TEST FAILOVER“ a „FAILOVER“. Rovněž zde můžete v části „Name“ změnit jméno budoucího virtuálního stroje. V další části je pak třeba specifikovat v jaké virtuální síti a jakém subnetu bude při proceduře „FAILOVER“ automaticky virtuální stroj umístěn. A případně jakou bude mít v daném subnetu IP adresu. Pokud IP adresu (TARGET IP ADDRESS) nevyplníte, dostane nastartovaný virtuální stroj IP adresu z Azure DHCP serveru. Změny uložte pomocí tlačítka „SAVE“. Poznámka: Tlačítko „SAVE“ a následná úloha, která se spustí v sekci „JOBS“ skončí s chybou v případě, že virtuální stroj byl již spuštěn v rámci procedur „TEST FAILOVER“ a „FAILOVER“. Pokud mají být nastartované virtuální stroje dostupné v On-Premise prostředí, je zde třeba nastavit virtuální síť, která je propojená s On-Premise prostředím prostřednictvím Site-to-Site VPN, nebo ExpressRoute.
**
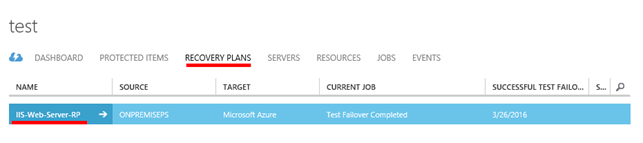
Nyní přejdeme k samotné proceduře „FAILOVER“. V sekci „RECOVERY PLANS“ vyberte váš RECOVERY PLAN a v dolní části okna klikněte na tlačítko „FAILOVER“.
**
**
Otevře se okno pro spuštění „FAILOVER“ procedury. Zde je nutné si vybrat především bod obnovení. Máme na výběr poslední bod obnovení, který byl replikován do Azure (Latest recovery point in time), nebo pak poslední aplikačně-konzistentní bod obnovení (Latest application consistent recovery point), nebo případně poslední „nekonzistentní“ bod obnovení (Latest crash consistent recovery point). Pokud v rámci virtuálních strojů běží aplikace, nebo služby využívající různé interní databáze apod., pak vždy doporučuji obnovit aplikačně konzistentní bod obnovení. Samozřejmě je třeba myslet v tomto případě na to, že aplikačně konzistentní body obnovený se vytvářejí v intervalech nastavených v rámci “PROTECTION GROUP”. A pokud tedy máte například nastaveno, že aplikačně konzistentní bod obnovení se provádí jednou za 4 hodiny, bude obnovený virtuální stroj a data na něm stará 4 hodiny! Což nemusí odpovídat již vašim požadavkům naRPO. Proto je třeba velmi důkladně zvážit nastavení v rámci konkrétní „PROTECTION GROUP“ i s ohledem na pozdější obnovu související s procedurou „FAILOVER“. Poslední volbou je pak „Shut down virtual machine(s) on-premies“. Tato volba vám umožní před spuštěním samotných virtuálních strojů v Azure, vypnout odpovídající virtuální stroje v On-Premise prostředí. Což je určitý bezpečnostní prvek pro případ „kolize“. Jako příklad si můžete představit situaci, kdy v rámci procedury „FAILOVER“ spustíte virtuální stoj replikovaný do Azure, který v On-Premise prostředí funguje jako doménový řadič a je rovněž držitelem všech FSMO rolí. A pokud je tento virtuální stroj spuštěný v Azure virtuální síti routované dále do On-Premis sítí, může případně dojít k vážným problémům.
Samozřejmě tato volba pozbývá významu v případě, pokud VMWARE virtualizace ve vašem prostředí nefunguje ať už z jakýchkoli důvodů a vy spouštíte proceduru „FAILOVER“ proto, aby jste On-Premise klientům zajistily kontinuitu služeb a aplikací.
**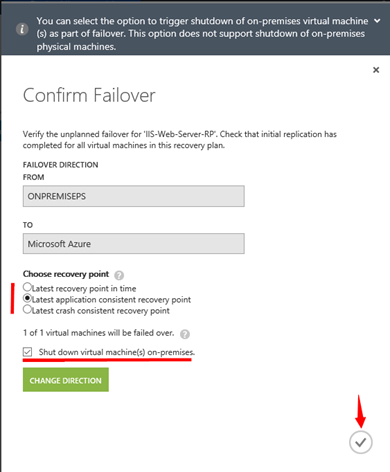
Já jsem vybral volbu „Latest application consistent recovery point“ a dále jsem povolil volbu. „Shut down virtual machine(s) on-premies“. A jak je vidět dále na obrázku z „tlustého“ klienta pro VMWARE, došlo v rámci procedury „FAILOVER“ k zastavení virtuálního stroje „IIS1“ v On-Premise prostředí.****
**
V sekci „JOBS“ lze pak nalézt běžící, nebo dokončenou úlohu procedury „FAILOVER“
**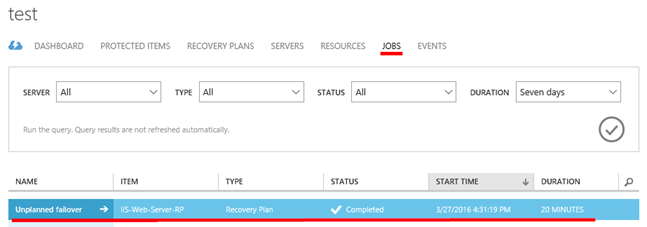
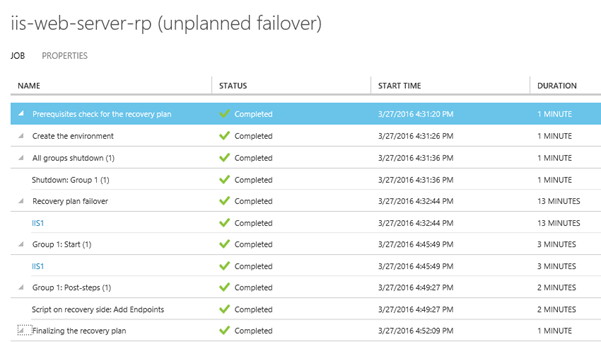
Pokud vstoupíme do této úlohy, uvidíme zde detaily. Mimo jiné vidíme, že došlo k úspěšnému nastartování virtuálního stroje v Azure a došlo rovněž k úspěšnému spuštění skriptu.
**
V původním portálu Azure pak v sekci „VIRTUAL MACHINES“ můžete vidět běžící virtuální stoje, spuštěné pomocí „RECOVERY PLAN“ a v rámci procedury „FAILOVER“.
**
Rovněž dojde automaticky k vytvoření Cloud Service, na který je navázána VIP IP adresa.
**
Pokud se vrátíme do sekce „RECOVERY PLANS“ vidíme, že plán je ve stavu „Unplanned Failover Complete“.
**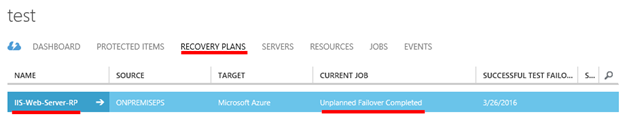
2.**Failback Pokud například v našem On-Premise prostředí došlo k dočasnému výpadku služeb, například z důvodu selhání HW nefungovala VMWARE virtualizace a my jsme provedly proceduru „FAILOVER“, tak po případném úspěšném obnovení normální činnosti VMWARE virtualizace, budete pravděpodobně chtít vrátit virtuální stroje do původního stavu. Tedy aby produkční virtuální stroje primárně běžely na VMWARE virtualizaci. K tomuto slouží proceduraFAILBACK. Ta umožnuje „obrátit“ replikaci dat a obnovit virtuální stroje v On-Premise prostředí do aktuálního stavu. Tedy dojde i k replikaci změn, které mezi tím nastaly při běhu virtuálních strojů v Azure do On-Premise prostředí. Poznámka: Základní předpoklad pro úspěšnou proceduru „FAILBACK“ je funkční Site-to-Site VPN (případně ExpressRoute) propoj, mezi Azure virtuální sítí a On-Premis sítěmi. Resp. skrze VPN spojení musí být dostupný On-Premise Management server (resp. Master Target server). Vybereme „RECOVERY PLAN“, který je ve stavu „Unplanned Failover Complete“. A v dolní části okna klikneme na tlačítko „RE-PROTECT**“.
**
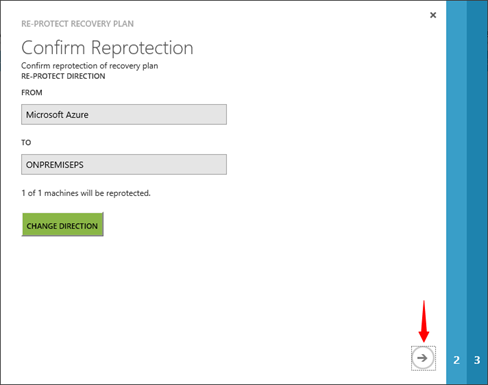
Spustí se průvodce procedurou „RE-PROTECTION“, kdy dojde ke změně směru replikace. A data budou replikována z Azure do On-Premise VMWARE virtualizace.
**
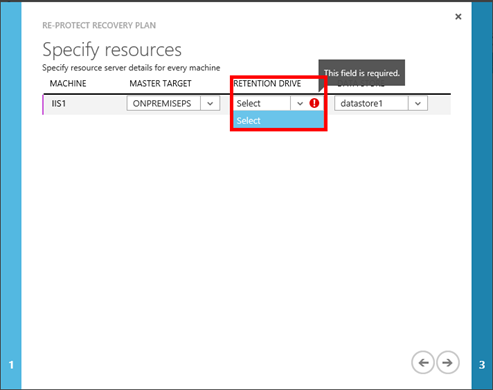
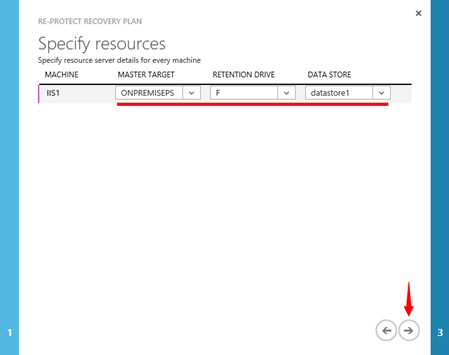
Na další kartě průvodce je pak nutné vybrat On-Premise „MASTER TARGET SERVER“ a dále „RETENTION DRIVE“ a „DATA STORE“. Kde „RETENTION DRIVE“ je virtuální disk na rychlých discích s „doporučenou“ kapacitou 600 GB, na který se ukládají dočasná replikační data související právě s procedurou „FAILBACK“.
A „DATA STORE“ je klasický „DATA STORE“ na VMWARE ESXi serveru, na který budou ukládány data. Ve výchozím stavu je nabídnut původní „DATA STORE“, ale je možné to změnit. Jak je vidět v tomto případě, nemám možnost vybrat „RETENTION DRIVE“. Důvody a řešení jsou popsány dále.
**
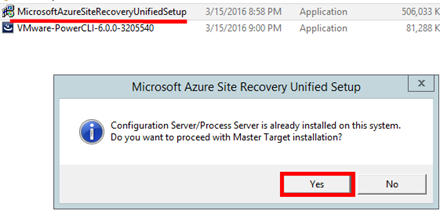
V mém případě jsem vytvořil virtuální On-Premise management server jen s jedním diskem s kapacitou 80 GB. Tak jak jsem upozorňoval v části zabývající se instalací Management serveru, kde třeba přidat datový disk na rychlých discích o dostatečné kapacitě, aby bylo možné realizovat proceduru „FAILBACK“. Po přidání datového disku je nutné provést restart management serveru. Poznámka: Disk je třeba naformátovat a přidělit mu písmeno!

Pokud se po přidání disku na management serveru v On-Premise prostředí změna neprojeví a to ani pro kliknutí na tlačítko „REFRESH“, je možné tuto změnu vynutit odinstalací komponenty „Master Target Server“. Následuje restart!
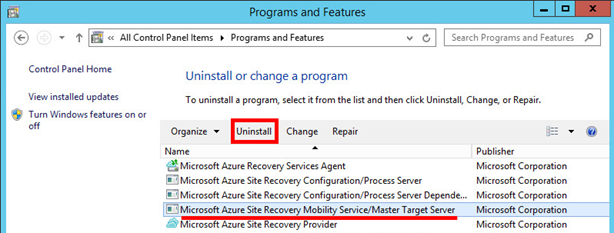
A následným spuštěním instalačního programu a opětovným doinstalováním „MASTER TARGET SERVER“. Následuje restart!
**
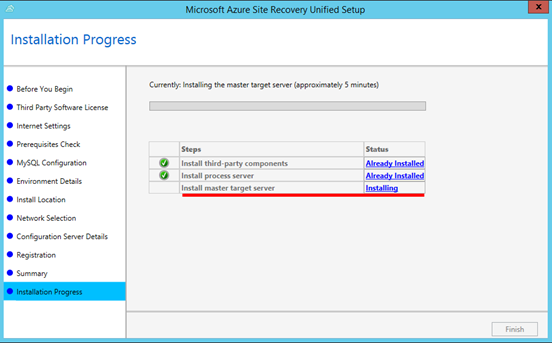
Poté je vhodné vynutit nahrání změn do ASR v Azure a to pomocí tlačítka „REFRESH“.

Pokud některý z postupů zafungoval, pokračujte v přechozí proceduře „RE-PROTECT“ a v tuto chvíli by měl být na výběr i „RETENTION DRIVE“.
**
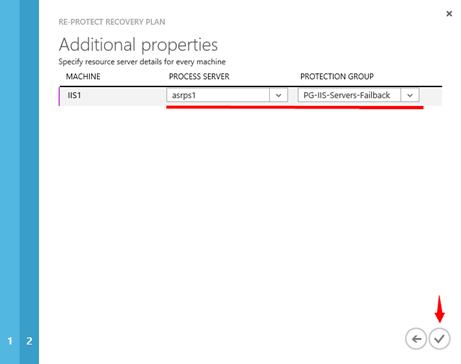
Na další kartě průvodce vybíráte „PROCESS SERVER“, který bude replikovaná data zpracovávat a dále PROTECTION GROUP, do které bude replikovaný virtuální stroj umístěn. Upozorňuji, že tato procedura v této fázi pouze obrací směr replikací! Co je velmi podstatné v této fázi je výběr „PROCESS SERVERU“. Jak je vidět na obrázku, já jsem vybral „PROCESS SERVER“ vytvořený jako virtuální stroj v Azure a zařazený do Azure virtuální sítě, která je propojená s On-Premise prostředím. Platí, že Management server v On-Premise prostředí musí být dostupný skrze VPN pro PROCESS SERVER umístěný v Azure!
Proč vlastně použít další PROCESS SERVER? No důvod je jednoduchý. Představte si situaci, kdy do Azure replikujete velké množství virtuálních strojů a tento velký objem dat zpracovává PROCESS SERVER běžící v On-Premise prostředí. No a vy zahájíte „RE-PROTECT“ proceduru a další velké množství dat bude zpracovávat tentýž PROCESS SERVER. Vytvoření dalšího PROCESS SERVERU je popsáno na konci tohoto článku.
Poznámka: Jinak platí, že jako PROCESS SERVER lze samozřejmě vybrat i PROCESS SERVER běžící na management serveru v On-Premise prostředí.
**
Zde pak vidíte příklad detail úspěšně proběhlé úlohy „RE-PROTECT“ v sekci „JOBS“.
**
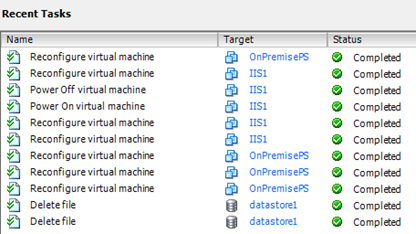
Na obrázku pak vidíte seznam úloh, které v rámci procedury „RE-PROTECT“ proběhly na samotném VMWARE vSphere serveru.
**
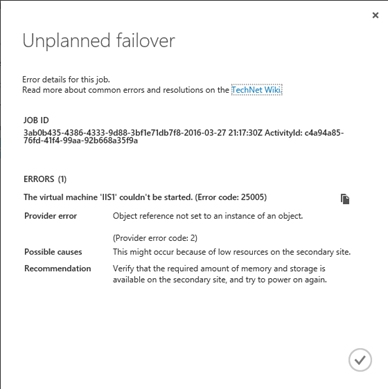
Pokud se pokusíte po dokončení „RE-PROTECT“ procedury spustit virtuální stoj ve VMWARE, dojde k vygenerování chyby. Ta odkazuje víceméně na problémy s virtuálním VMDK diskem. Což je v tuto chvíli v pořádku. An error was received from the ESX host while powering on VM IIS1. Failed to start the virtual machine. Module DiskEarly power on failed. Cannot open the disk '/vmfs/volumes/568cf58d-8f56357a-c9d4-b8ac6f8507ac/IIS1/IIS1.vmdk' or one of the snapshot disks it depends on. Failed to lock the file
Pokud tedy úloha v sekci „JOBS“ byla úspěšně dokončena, přesuneme se do sekce „PROTECTED ITEMS“ – „PROTECTION GROUPS“ kde je z obrázku patrné, že virtuální stroj se přesunul do druhé „PROTECTION GROUP“ s označením „Failback“ na konci názvu. Vstoupíme do této skupiny.

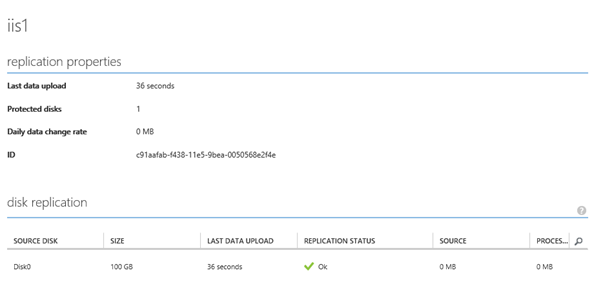
Jak je patrné z obrázku aktuálně dochází k postupné synronizaci/replikaci dat z Microsoft Azure do On-Premise prostředí na VMWARE ESXi server. Je důležité poznamenat, že tato synchronizace může trvat i poměrně dlouho. Je to závislé od toho, kolik dat se od doby spuštění procedury „FAILOVER“ na virtuálním stroji běžícím v Azure změnilo. Navíc dokud se tato replikace nedokončí, není možné dokončit samotný „FAILBACK“ a virtuální stroj v On-Premise prostředí nepůjde použít.

Zde je pak vidět detail samotného virtuálního stroje, který se replikuje zpět do On-Premise prostředí
**
Ve chvíli kdy se změna směru replikace z Azure do On-Premise prostředí dokončila, je možné přistoupit k dokončení samotného „FAILBACK“ a zprovoznit produkční virtuální stroj opět na VMWARE ESXi serveru.
**
Přejděte opět do sekce „RECOVERY PLANS“, vyberte konkrétní plán, který je ve stavu „Unplaned Failover Completed“ a tentokrát ve spodní části okna klikněte na tlačítko „FAILOVER“.
**
**
**
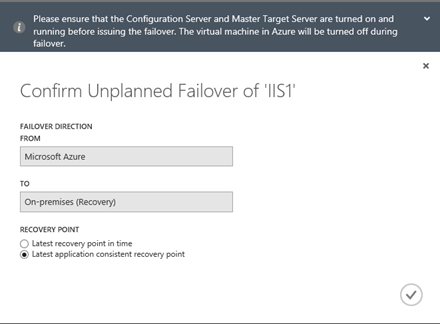
Spustí se okno potvrzení procedury „FAILOVER“ kde pak aktuálně vidíme, že tentokrát je zdrojem Azure a cílem je On-Premise prostředí. V mém případě jsem vybral „Latest application consistent recovery point“.
**
Pokud vše proběhlo v pořádku a VPN je funkční, dojde automaticky v rámci úlohy k doreplikování změn a automaticky dojde ke spuštění virtuálního stroje v On-Premise prostředí ve VMWARE virtualizaci.
**
****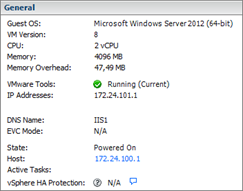
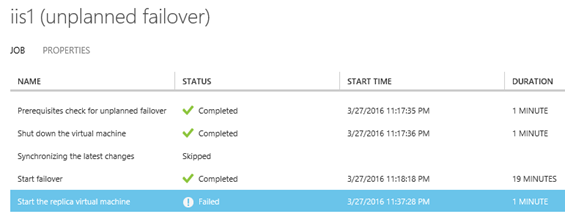
I když úloha na konci vygenerovala chybu, viz pak obrázek níže, i tak se zdá být vše v pořádku a virtuální stroj v On-Premise prostředí se zdá být v pořádku a operační systém také v pořádku naběhl.****
**
**
Určitou zvláštností je, že i po dokončení „FAILBACK“ zůstane v Azure vypnutý virtuální stroj.
**
3.**Reprotekce zpátky do Azure
Pokud již máme nazpět funkční virtuální stroj v On-Premise prostředí, je vhodné jej znovu začít synchronizovat do Azure, právě pro případ dalšího možného výpadku v On-Premise prostředí. Proto provedeme proceduru „RE-PROTECT“ a obnovíme replikaci virtuálního stroj zpět do Azure.
Poznámka: Níže uvedenou proceduru lze provést i v rámci „RECOVERY PLAN“.
Tedy v sekci „PROTECTED ITEMS“ – „PROTECTION GROUPS“ vstoupíme do skupiny, která na konci názvu označení „failback“. A vybereme konkrétní virtuální stroj. Následně v dolní části okna klikneme na tlačítko „RE-PROTECT“.

**
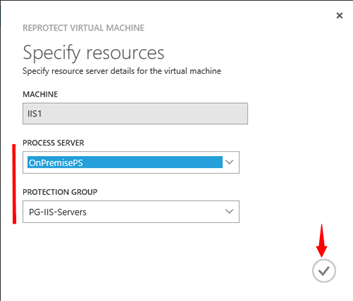
Zobrazí se okno s nastavením. Kde opět definujeme PROCESS SERVER a PROTECTION GROUP, jehož součástí bude replikovaný virtuální stroj.
**
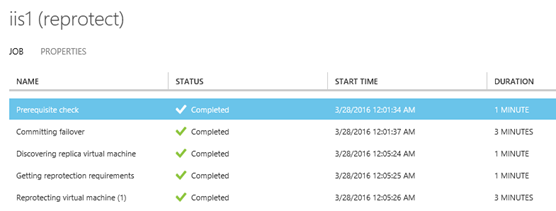
Zde pak ukázka úlohy úspěšně provedené RE-PROTECT.
**
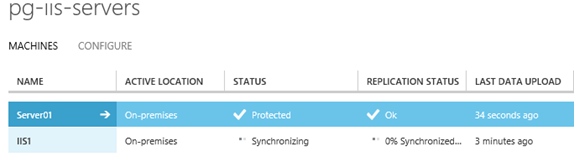
Následně v dané PROTECTION GROUP jde vidět, že nám přibyl virtuální stroj a zahájila se replikace dat do Azure. A co je zajímavé v této fázi zmizel virtuální server z Azure, ze seznamu virtuálních serverů.
**
4.**Přidání Process serveru v Azure
Jak již bylo v článku výše napsáno, je možné do samotného Azure přidat další PROCESS SERVER. Cílem této akce je pak primárně při proceduře „FAILBACK“ „odlehčit“ zátěž primárnímu PROCESS SERVERu v On-Premise prostředí.
Přejdeme do sekce „SERVERS“ – „CONFIGURATION SERVERS“. V dolní části okna pak klikneme na tlačítko„+ PROCESS SERVER**“
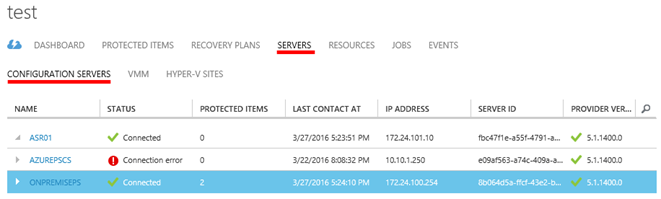

Zobrazí se okno přidání nového PROCESS SERVERu do Azure. Vyplňte parametry pro nový server. V této fázi je třeba si dát pozor na jednu zásadní věc. Ve chvíli kdy zadáte do pole „PROCESS SERVER NAME“ nějaký název, ten se neprověřuje! Tedy je třeba jednak vymyslet unikátní název v rámci celého Azure! a dále se musí jednat paradoxně o unikátní název z hlediska názvu storage accountu. Jak je v průvodci vidět, resp. vlastně není vidět položka pro zadání názvu storage accountu. Znamená to tedy, že se nejprve v rámci úlohy snaží Azure založit storage account s názvem stejným jako je uvedeno v poli „PROCESS SERVER NAME“. Proto je vhodné nejprve separátně založit nový storage account a pokud je název volný, použit stejný název i pro nový PROCESS SERVER. Poznámka: Tento nový PROCESS SERVER musí mít skrze VPN spojení s On-Premise prostředím!


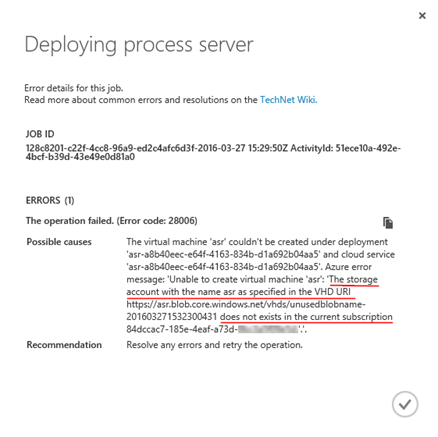
Pokud je jméno strage account již obsazeno, skončí úloha s poněkud matoucí chybou.

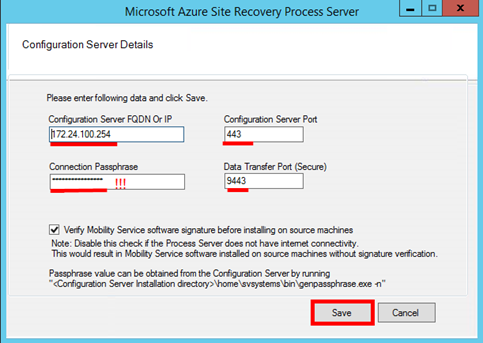
Ve chvíli kdy je PROCESS SERVER dostupný/vytvořený, přihlaste se skrze vzdálenou plochu. Automaticky dojde napoprvé ke spuštění konfiguračního utility PROCESS SERVERu. Zde je nutné vyplnit IP adresu On-Premise PROCESS SERVERu, komunikační port (standarně TCP 443) a co je nejpodstatnější, je třeba zde doplnit správnou Passphrase. Ta byla vygenerována při instalaci On-Premise management serveru. Pokud existuje VPN konektivita mezi Azure virtuální sítí a On-Premise sítí, kde se nachází PROCESS SERVER, klikněte na tlačítko „Save“ a mělo by dojít ke spárování obou PROCESS SERVERů.
Užitečné odkazy: https://azure.microsoft.com/en-us/documentation/articles/site-recovery-vmware-to-azure-classic/#step-6-set-up-credentials-for-the-vcenter-server https://azure.microsoft.com/en-us/documentation/articles/site-recovery-failover/ https://azure.microsoft.com/en-us/blog/introducing-powershell-support-for-azure-site-recovery/ https://azure.microsoft.com/cs-cz/documentation/articles/site-recovery-runbook-automation/