Co to je Automatický Storage Tiering
Ještě před několika lety využívaly společnosti většinou jeden či dva terabajty diskového prostoru. Množství vytvořených a uložených dat se však každý rok zvětšuje exponenciálně.
Mezi největší konzumenty datového prostoru se řadí videa v HD kvalitě, rentgenové snímky, fotografie či virtuální servery. Problém je, že většina dat uložených v současnosti jsou tzv. nestrukturovaná data, tedy data, ke kterým máme jen málo informací pro lepší automatické třídění viz obr. 1. V současnosti tak nejsou vyjímkou společnosti, které na svých diskových polích udržují více než 50TB dat.
Automatický Storage Tiering
dříve známý spíše jako HSM (Hierarchical Storage Management) viz http://en.wikipedia.org/wiki/Hierarchical_storage_management..
Při těchto datových objemech jsou již společnosti postaveny před nelehký úkol – uchovávat stále rostoucí množství informací a současně k nim zajistit okamžitý přístup tak, aby uživatelé i aplikace mohli pracovat rychle a bez čekání. Další položka v diskových polích jsou tzv.IOPS viz. http://en.wikipedia.org/wiki/IOPS.
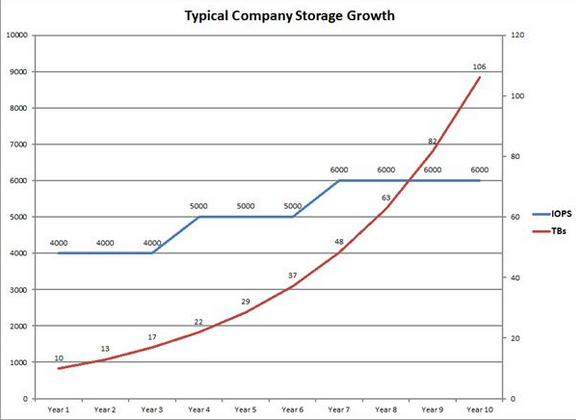
IOPS jsou ve společnosti většinou statické a v čase neměnné (pouze spuštění nové aplikace atp. může vyžadovat vyšší IOPS) oproti téměř exponenciánímu růstu kapacity. Viz obr.2, kde vidíme poměrně konzervativní 30% meziroční nárůst kapacity oproti téměř konzistetním IOPS. Kapacita se nejlépe řeší velkými, ale pomalými nlSAS HDD. Jak dosáhnout kombinace IOPS a kapacity s ohledem na to, že kolem 70% dat, která mám, jsou statická a tudíž k nim nepotřebuji pravidelně přistupovat?
Dnes se blíže podíváme na technologii diskových polí, jejímž cílem je právě řešení výše uvedeného dilematu. Problém s ukládáním dat si můžeme představit například takto: Máme několik důležitých virtuálních serverů, které nám na diskovém poli dohromady zabírají cca 2TB a vyžadují 1500 IOPS. Aby servery pracovali svižně, uložíme jejich data na 10ks pevných disků SAS s rychlostí 15 000 otáček (počítejme, že jeden disk má 150 IOPS) a kapacitou cca 600GB na disk. Tuto skupinu disků „naformátujeme“ pomocí RAID10. Tento typ RAID je nejvýkonnější, ale také nejméně efektivní. Jeho efektivita je 50%, využijeme tedy jen ½ zakoupeného místa. V našem případě je to tedy 3TB před formátováním. Vznikne nám prostor pro náš původní požadavek 2TB i s prostorem pro určitý růst.
Problém nastane ve chvíli, kdy se nám servery začnou rozrůstat, ať už do počtu(IOPS) či objemu(TB). Velmi brzy přesáhneme kapacitu našich 10-ti disků a bude potřeba dokoupit disky další, aby nám nedošlo místo. Brzy však pochopíme, že takové řešení nelze aplikovat do nekonečna, neboť pro uložení 50TB dat nám při této konfiguraci vychází, že musíme zakoupit cca 160ks pevných disků. A to už je docela velké číslo.
Problém však lze řešit i jinak: Jak jsme si již řekli na začátku článku, ze statistických měření vychází, že velká část uložených souborů je pouze statická. Nejen, že se nemění z hlediska obsahu, ale kolikrát také nejsou za celý rok ani jednou otevřeny a přečteny. Stejná situace platí i v databázích, kde malá část databáze bývá velmi intenzivně využívána aplikacemi, zatímco historické záznamy jsou pouze uloženy a pracuje se s nimi zcela minimálně. Krásný příklad si můžeme udělat na emailech. Určtě sami potvrdíte, že aktivně využíváte pouze malé procento emailů a zbytek tam pouze čeká pro případ, kdybyste se náhodou k nim potřebovali v budoucnu vrátit. Nebylo by tedy finančně výhodnější využít nějaký automatizovaný systém, který toto rozpozná a sám místo nás přesune tyto nepoužívané emaily na cenově výhodnější medium?
Diskové pole vybavené funkcí automatického storage tieringu dokáže samo rozpoznat, které části souborů či databází jsou využívány intenzivně, které méně a které nejsou využívány vůbec. Všechny datové segmenty se pak rozdělí na „horké“ či „studené“. Horké segmenty diskové pole automaticky přemisťuje na rychlé pevné disky, v našem případě tedy disky 600GB SAS 15 000 otáček. Naopak studené segmenty se začnou přemisťovat na levné velkokapacitní disky, např. 2TB nlSAS. Zatímco většina diskových polí, která umí automatický storage tiering zde končí, ta chytřejší pole jdou ještě dále: Při přesunu na levnější disky rovnou změní typ RAIDu, viz. http://en.wikipedia.org/wiki/RAID, pod kterým je daný datový segment uložen. Studené segmenty se tak mohou nakonec dostat až na RAID5, který je sice pomalejší na zápis, nicméně poskytuje mnohem větší užitnou kapacitu než rychlý RAID10. Data, která jsou pak ještě delší dobu neaktivní, se mohou přepočítat na RAID6, který má ještě větší ztrátu výkonu při zápisu, ale poskytuje dvojitou ochranu před výpadkem.
V našem příkladu tak při použití chytré technologie budeme k uložení 50TB dat potřebovat cca 10ks disků 600GB SAS a 32ks disků 2TB SATA. Z ekonomického hlediska pak bude pořízení i rozšiřování chytrého pole mnohem levnější, než původní varianta se 160-ti pevnými disky. Přitom bude stále zajištěno, že naše aplikace nám poběží tak rychle, jak potřebujeme.
S nadsázkou se dá říci, že je to podobné jako ve světě automobilů: Výkonné auto může být klasická amerika s benzínovým motorem o obsahu 5 litrů. Nebo také evropský sporťák s dobře vyladěným turbem.
Není Tiering jako Tiering
jaké známe typy Tieringu
LUN TIERING
LUN (Logical Number Unit) viz. http://en.wikipedia.org/wiki/Logical_Unit_Number Tento Tiering spočívá v tom, že na základě statistik o vytížení konkrétního LUNu jej diskové pole může celý přemístit na pomalejší disky, případně vrátit zpět na disky rychlé. Velkou nevýhodou tohoto způsobu je, že se přemisťuje celý LUN buď na rychlé, nebo na pomalejší disky a rozlišování mezi horkými a studenými segmenty tak není možné.
Přirovnání: Pokud bychom si představili kuchyňskou linku (diskové pole) a v ní šuplíky (LUNy), v každém šuplíku jsou různé věci (data). Představme si např. šuplík, kde jsou příbory spolu s nástavci na mixování. Protože příbory používáme velice často tak je logické, že si dáme tento šuplík nejblíže dostupnosti našich rukou, abychom k nim přistupovali s nejmenší energií a nejrychleji (SAS nebo SSD). Problém ale je, že přesouváme celý šuplík, včetně nástavců na mixování, které využijeme jen párkrát za měsíc. V reálném světě bychom tyto věci dali na nějaké jiné místo níže a dále dostupné (levnější a pomalejsí nlSAS), což v tomto případě právě nejde.
SSD Cache
Nejedná se o tiering v pravém slova smyslu, neboť data se přemisťují okamžitě. Automatický Storage Tiering je funkcionalita, která z principu věci funguje v nějaké časové periodě, kdy pole pozoruje chování dat a na základě dlouhodobějších pozorování teprve následně provádí změny. Cache oproti tomu funguje okamžitě, pouze ta nejčastěji využívaná data jsou načtena do dočasného vyrovnávacího prostoru na rychlých discích SSD. Toto řešení je velmi jednoduché a dokáže výrazně zlepšit odezvu aplikací. Proto je často používáno u výrobců diskových polí, kteří nejsou v oblasti Tieringu ještě na úrovni SUB-LUN (viz. níže) nebo s tieringem ještě vůbec nezačali.
Jednou z jeho nevýhod, pomineme-li vysokou cenu, je to, že SSD cache bývá poměrně malá (řádově stovky GB). Je-li pak diskové pole delší dobu vystaveno větší zátěži, dojde k přetečení cache a nejstarší datové segmenty se musí z cache odstranit. SSD cache je tedy vhodná zejména pro pokrytí výkonových špiček nebo do prostředí, kde není vysoký výkon vyžadován trvale. Další nevýhodou jsou občasné operace, představme si např. Business Intelligence analýzu, kterou si nechá spustit generální ředitel. Tato analýza projede všechna data v databázi (a ne jen ta nejčastěji používaná) a tato způsobí, že cache přeteče a diskové pole se vrátí do stavu jako by tam vůbec nebyla. Naopak výhoda je, že se toto děje na úrovni diskového bloku viz.http://en.wikipedia.org/wiki/Block_(data_storage))
Přirovnání: Pokud se opět vrátíme do naší již zmiňované kuchyně. Je to situace, kdy ten nejbližší šuplík na příbory, který je pro nás nejrychleji dostupný, uděláme prázdný. Potom cokoli budeme brát z jakéhokoli místa přesuneme nejdříve do tohoto šuplíku a pak teprve vezmeme. No myslím, že už začínáme vidět výhody a nevýhody tohoto systému. Jednoznačně je tam drobné prodlení při „plnění“ šuplíku. Další věc je ale to, že jakmile se mi šuplík zaplní, musím začít řešit situaci, abych tam mohl dát novou věc musím tu nejstarší vrátit zpátky na její původní místo. Tzv. FIFO (First In First Out) viz.http://en.wikipedia.org/wiki/FIFO . Dá se tedy jednoduše shrnout, že po vytvoření tohoto řešení mám určité období, kdy mám velký přínos, nicméně po zaplnění se začíná ztrácet.
SUB-LUN Tiering
Je pokročilým způsobem automatického storage tieringu. Pracuje na úrovni segmentů o velikostech od několika kB do několika GB. Čím jsou segmenty menší, tím lepší bude efektivita celého systému. Horké segmenty jsou umístěny na rychlé pevné disky, studené segmenty se přemístí na disky pomalejší. Je-li diskové pole opravdu chytré, dokáže během přesunu změnit i typ RAIDu tak, jak bylo uvedeno v našem příkladu na začátku. Jednodušší disková pole musí během přesunu zachovávat stejný RAID na všech typech disků, což má negativní dopad na efektivitu i cenu diskového pole. Např. zvolím RAID10 pro maximální rychlost zápisu na rychlých discích SAS 4x146G 15K (kapacita věnovaná redundanci je tedy 292G) a to samé musím tedy zvolit na velkokapacitních 4x2TB 7,2K nlSAS HDD (kapacita obětovaná redundanci je zde hrozivých 4TB! oproti RAID5, kde by v této konfiguraci byla o 50% menší! Čím více disků, tím větší úsporu bych dosáhl).
Co je důležité! Vzhledem k tomu, že se jedná o přesun mnohdy velkého množství dat, spotřebuje to také nějaký výkon na diskovém poli. Tyto operace se sice většinou provádějí v tzv. Idle modu, nicméně velikost přesunovaných dat je zde nejdůležitějším parametrem. Diskový blok (viz. výše) je v diskových polích většinou kolem 64kB. Žádný výrobce na trhu ještě není na úrovni, aby byl schopen přesunovat diskové bloky. Proto vznikl pojem page, jedná se o skupinu bloků. Platí tedy, čím menší page tím větší granularitu jsem schopen dosáhnout, tím lepší efektivity dosáhnu. Díky neustálému zvyšování výkonu procesorů a ostatních parametrů se oblast může neustále zmenšovat. Pro srovnání jsou na trhu disková pole, která mají page velikosti 1GB! To je více než co se vejde na CD-ROM (700MB). Dobrá řešení jsou na úrovni jednotek MB. Špičková řešení v této oblasti se pohybují kolem 512kB (pro srovnání je to 2000x menší datová oblast, než již zmíněný 1GB!)
Přirovnání : Toto je příklad, který se nám nejvíce blíží realitě v již zmiňované kuchyni. Příklad z LUN Tieringu. Tedy šuplík s příbory a nástavci na mixer. Zde diskové pole udělá v podstatě to, co bychom udělali i v realitě. Přesune POUZE nástavce na mixer do vzdálenějšího šuplíku a nechá tam příbory které jsou často používané.
BLOK LEVEL TIERING
Tento typ Tieringu, jak již bylo zmíněno výše, zatím není dostupný. Nicméně koncem roku se můžeme těšit na prolomení této bariery. Jak zmínil Steven Dahlin, Dell EMEA Sales Manager Compellent, na CeBitu : http://www.theregister.co.uk/2011/03/02/compellent_64_bit_granularity
Update : Termín uvolnění nového FW Storage Center 6.0 (aka 64bit) je 9.1.2012
Přirovnání : Opět se vrátíme do naší kuchyně. Zde bude pak možno jít až na úroveň každého příboru nebo typu nástavce mixeru. Máme-li v oblibě mixované nápoje, určitě by bylo vhodnější umístit tento nástavec blíže než ostatní, rozdělit tedy nástavce na další podúrovně. Tento příklad je v praxi asi nereálný, protože jsme omezeni lidským mozkem a nutilo by nás to zapamatovat si, co kde je. Toto je něco, co se v počítačovém světě děje v jakékoli velikosti page, pokud půjdeme na úroveň bloku, musí si diskové pole toho pamatovat více. Proto je nutný 64bitový systém v diskovém poli, aby bylo pole schopno takovouto spoustu informací adresovat. Viz. http://en.wikipedia.org/wiki/X86-64
Jak vybírat vhodný tiering
Rozhodneme-li se pro pořízení diskového pole s technologií automatického storage tieringu, je vhodné zjistit si dopředu několik základních parametrů:
-
Jaký typ tieringu pole skutečně podporuje?
-
Jak velký je segment, se kterým tiering pracuje?
-
V jaké periodě probíhá vyhodnocování ?
-
Umí storage poznat pravidelné operace, které automaticky vyřadí z hodnocení ?
- Umí technologie během tieringu měnit typ RAIDu?
Autoři: Ondřej Bajer, Dell Storage Sales Specialist, Ondřej Bačina, Dell Enterprise Brand Manager