Nedávno se na webu společnosti Veeam objevil nový produkt, který umožňuje obnovu VM ze záloh Veeamu v prostředí Azure a který je zdarma a je dostupný v rámci Marketplace Azure. Zálohu virtuálního stroje je možné získat pomocí standardního produktu Veeam Backup and Restore verze 9 (placené či free verze) nebo fyzického stroje pomocí Veeam Endpoint Backup (verze 1.1). Takto získaný soubor se zálohou překopírujte do prostředí Microsoft Azure. Na adrese https://helpcenter.veeam.com/backup/restore_t...
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou....
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou....
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou....
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou....
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou....
Připravil jsem pro vás sérii článků, zabývající se technologií Azure Site Recovery. Konkrétně v šesti na sebe navazujících článcích se dozvíte, jak správně nasadit Azure Site Recovery. Postupně vás tyto články od začátku provedou celým procesem a to od samotné instalace a nastavení potřebných komponent, po obnovení virtuálních strojů po výpadku produkčního prostředí. Všechny na sebe navazující články pak budou popisovat spolupráci Azure Site Recovery v kombinaci s VMWARE virtualizační platfomou....
V rámci Microsoft Azure, existuje mnoho částí/komponent IaaS (Infrastructure as a Service) infrastruktury, které poskytují zajímavou funkcionalitu z hlediska nasazení širokého spektra různých aplikací. V tomto článku se budeme postupně zabývat nasazením Externího Load Balancingu, Interního Load balancingu a Traffic Managera. S tím, že nakonec společně skombinujeme Externí Load Balancing s Traffic Managerem. Všechny tyto „komponenty“ pak souvisejí se síťovou částí IaaS. Vysvětlení pojmů: (Po...
Zřejmě jste se již někdy setkali s pojmem Azure Recovery Services a asi víte, že pod ně spadají služby Azure Backup a Azure Site Recovery, které vám umožní v Azure jednoduše zprovoznit Backup-as-a-Service a Disaster Recovery-as-a-Service. Pojďme si podívat, o co se vlastně jedná, pro koho je služba vhodná a také se zaměříme na novinky, které se objevily na přelomu tohoto roku.
Azure Backup
Pojďme se nejprve podívat na Azure Backup a jeho možnosti zálohovat systémy on-premise, tak i virtuální...
PowerShell je velmi silný a efektivní způsob skriptování, který se postupně rozšířil nejen pro ovládání všech novějších produktů Microsoftu, ale i produktů od jiných výrobců (https://en.wikipedia.org/wiki/Windows_PowerShell#Application_support). Od verze 2.0 lze PowerShell používat i pro vzdálené volání powershellových příkazů. Tzv. remoting umožňuje vzdálená volání procedur z lokálního počítače včetně paralelního zpracování dotazů. Veškerá komunikace je šifrovaná.
Remoting lze iniciovat pří...
Během praxe se vám může stát, že po smazání některého z virtuálních strojů, kdy ponecháte nesmazaný disk, nebo za určitých specifických podmínek může dojít k “zablokování” vhd souboru disku virtuálního stroje. A tento disk nejde smazat a tím pádem nejde smazat také storage account, tak jak to vidíte na obrázku níže.
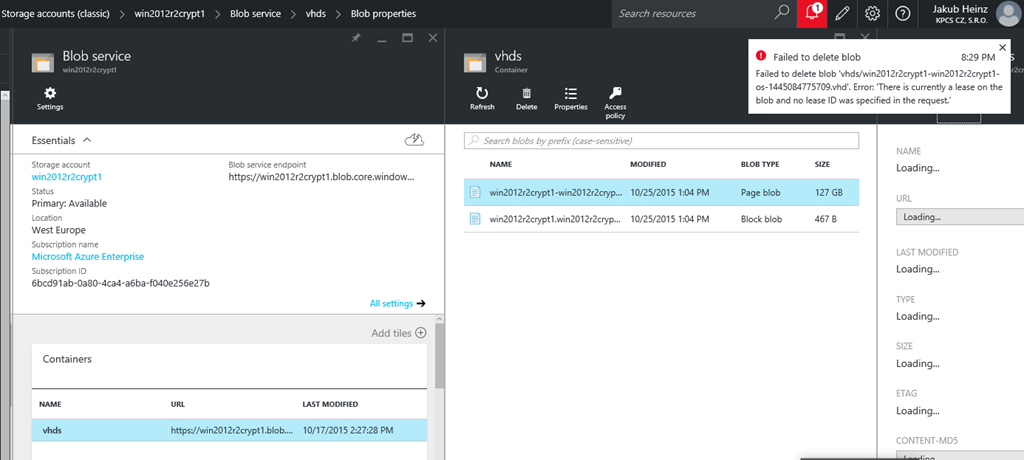
Jak si to ověřím..?
-
Stáhněte si CloudBerry Explorer, který je zdarma
http://www.cloudberrylab.com/free-microsoft-azure-explorer.aspx?ad=menu-products-explorer-azur...
Dalším důkazem toho, že to společnost Microsoft myslí s podporou Linux operačních systému v Azure velmi vážně, je nově zveřejněná certifikační zkouška zaměřená na Linux operační systémy. Certifikační zkouška “MCSA: Linux on Azure” se skládá ze zkoušky 70-533 a zkoušky LFCS. Více informací lze nalézt zde: https://www.microsoft.com/en-us/learning/mcsa-linux-azure-certification.aspx https://channel9.msdn.com/Events/Ignite/2015/BRK3901 http://www.azureman.com/certification/azure-...
Tímto článkem navazuji na můj přechozí článek popisující nastavení RBAC (Role-based access control) v Microsoft Azure. Jen shrnu, že RBAC umožnuje nastavit Role pro konkrétní uživatele, nebo skupiny a na základě této role, má pak konkrétní uživatel možnost provádět konkrétní akce. Tedy například vytvořit virtuální stroj, nebo jej spustit. Pořád platí, že role a RBAC je možné nastavit jen v novém portálu https://portal.azure.com Ovšem standardně jsou v Microsoft Azure na výběr jen předvytvořené...
Microsoft nedávno uvolnil v režimu Preview, funkcionalitu která vám umožní v kombinaci s Key Vault šifrovat disky virtuálních strojů v Microsoft Azure.
POZOR! Jedná se o režim „Preview“. Tedy jedná se o počáteční implementaci v režimu testování, kde platí, že tato funkcionalita by neměla být aplikována na produkční prostředí!
Ve chvíli, kdy společnost Microsoft oznámí, že tato technologie je dostupná jako GA (General Availability), teprvé pak je vhodné tuto technologii nasadit na p...
Společnost Microsoft včera převedla Azure Preview Portál z režimu “Preview” do režimu “GA”. To tedy znamená, že nejen že zmizelo označení “Preview”, ale od této chvíle je nový portál https://portal.azure.com považován za primární portál pro práci s Microsoft Azure! A i nadále bude pokračovat trend, kdy veškeré nové funkcionality a vylepšení budou dostupné pouze skrze tento nový portál, nebo pak skrze Azure PowerShell. Stále ale platí, že je možné pracovat s původním portálem http://mana...